Squeezing More Out of Vec2Text with Embedding Space Alignment 🧃
Transferring previously-trained Vec2Text’s embedding inversion to new text encoders.
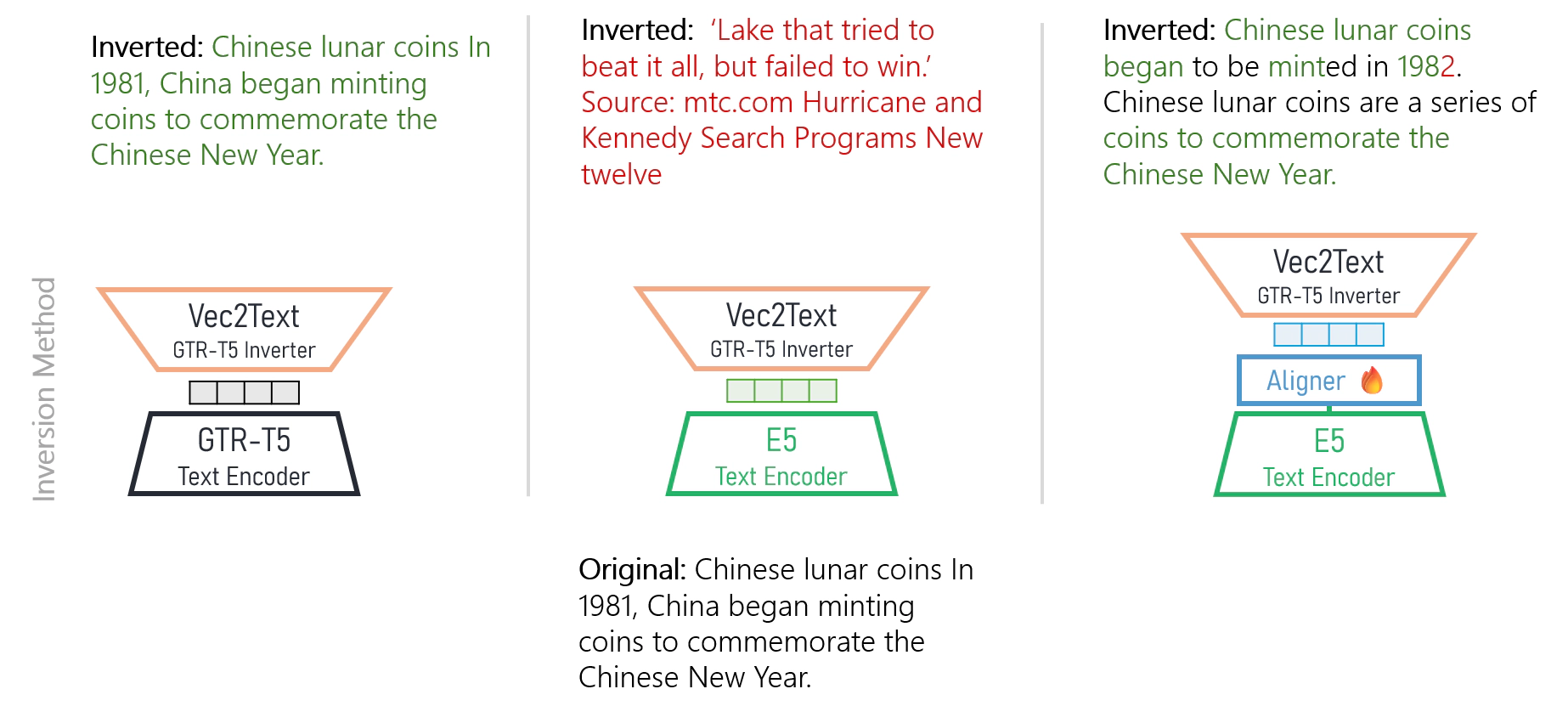
TL;DR: Instead of costly retraining Vec2Text—a known method for textual-embedding inversion—for applying it on new encoders, we map their embeddings to GTR’s (encoder for which Vec2Text is already trained on) via a single linear layer, finding it enables a limited text reconstruction of their embeddings, i.e., of key ideas and words.
Overview
In a recent work, Morris et al. introduced Vec2Text showing it is possible, under certain yet reasonable conditions (e.g., short text), to perfectly reconstruct text given with its corresponding embedding vectors. This method is based on a seq-to-seq inverter model (T5, in this case), which iteratively refines the reconstructed text, following the intermediate embeddings; training such a model for additional text encoders is computationally expensive and engineering-effort requiring. Our goal in the following post is attempting to get the best of both worlds—extend the inverter model to new text encoders, while keeping the training process simple and efficient.
To this end, we reuse an already-trained inversion, by mapping other encoders to the invertible embedding space; such reuse can be seen as transferring the inversion attack on one model to another. Concretely, as the original work of Vec2Text is trained to invert GTR embeddings, we map different text encoders (source) onto GTR’s embedding space (target), then utilize this mapping to perform inversion of these text encoders.
In what follows we first introduce the concept of aligning embedding spaces of text encoder, we then employ the alignment to map text encoder onto the embedding space of a text encoder already-invertible by Vec2Text, and evaluate the success of the inversion.
Method: Mapping from one embedding space to another (“Alignment”)
Ideally, we aim to perfectly map the embeddings of a source text-encoder model to the embeddings of the target text encoder using an aligner, $f$ . Formally, we look for: $${\arg min}_{f} \mathbb{E}_{t\sim \mathit{Texts}}\left [\left\Vert Emb_{\mathit{target}}\left(t\right)-f\left(Emb_{\mathit{source}}\left(t\right)\right)\right\Vert _{2}^{2}\right] $$
Notably, the optimization is done w.r.t. a distribution of texts (denoted as $\mathit{Texts}$), e.g., the distribution of Wikipedia paragraphs. Additionally, this method is black-box–it does not require the model weights or gradients—and as such can be applied on close-sourced proprietary embedding models (e.g., OpenAI’s).

Employing the Alignment to reuse Vec2Text
As Vec2Text was already extensively trained to invert GTR, we map new text encoders (source) to GTR’s embedding space (target).
To this end, we train the mapping $f$ (aligner) to optimize the objective above; for training samples (i.e., $\mathit{Texts}$ distribution), we take the 5.33M passages of the Natural Questions corpus, also used to train the inversion method of Vec2Text.
Results
Some (cherry-picked) examples of inversions, from NQ corpus (were not part of the training). Here, GTR is the model originally train to be inverted and we attempt to invert the embeddings created by E5 via linear alignment:
- “Oregon Desert Trail: The Oregon Desert Trail is a network of trails, cross country travel and two-track dirt roads across the Ore”
Inversion from GTR
Oregon Desert Trail: The Oregon Desert Trail is a network of trails, cross country travel and two-track dirt roads across the Ore
Inversion from E5+Aligner
Oregon Desert Trail () is the two-track road and travel network in and around the desert. Cross-Cross-Oregon and Gold
- “The World Methodist Council, an association of worldwide churches in the Methodist tradition, of which the AME Church is a part,”
Inversion from GTR
The World Methodist Council, an association of worldwide churches in the Methodist tradition, of which the AME Church is a part,
Inversion from E5+Aligner
The World Methodist Church is an American Methodist Council representing members of the Alliance of Methodist Churches of Europe (AME) is an international tradition associated with Methodist
- “District of Columbia Court of Appeals: The District of Columbia Court of Appeals is the highest court of the District of Columbia”
Inversion from GTR
District of Columbia Court of Appeals: The District of Columbia Court of Appeals is the highest court of the District of Columbia
Inversion from E5+Aligner
Court of Appeal for the District of Columbia Supreme Court The Court of Appeal for the District of Columbia Supreme Court is the district court’s highest court in the
We see that the main idea is consistently extracted, however we never observe full and exact reconstruction of the text. Indeed, from quantitative results we reaffirm these trends. Further evaluation, description of the metrics and additional models, in the report.
| source Model | Aligner $f$ | Cos. Sim. (Nomic) | Token F1 | Exact Match |
|---|---|---|---|---|
| GTR | - | 0.98600 | 92.489% | 20.6% |
| E5 | - | 0.46163 | 9.874% | 0% |
| E5 | Linear | 0.77026 | 29.316% | 0% |
We note that these results can be further improved via optimizing the choices of training $\mathit{Texts}$ distribution, adjusting the alignment process for the inversion task, or slightly enhancing the aligner’s architecture (while maintaining efficiency).
Takeaways
Results show that while full-scale training of the Vec2Text method can provide high-quality embedding inversion, by training a mere linear layer it is possible to efficiently yet limitedly extend this capability to other text encoders. This may also suggest of the “similarity” of these embedding spaces.